41 variational autoencoder for deep learning of images labels and captions
TensorFlow Autoencoder Tutorial with Deep Learning Example - Guru99 The other useful family of Autoencoder Deep Learning is variational autoencoder. This type of network can generate new images. Imagine you train a network with the image of a man; such a network can produce new faces. How to Build an Autoencoder with TensorFlow. In this tutorial, you will learn how to build a stacked autoencoder to reconstruct an image. shan-noob/Deep-Steganography-using-Autoencoders - GitHub An auto encoder-decoder based deep convolutional neural network is proposed to embed the secret image inside the cover image and to extract the file There are several image encryption methods currently out there, but few require the automation of the secret key generation process utilizing an unsupervised learning mechanism.
Deep Variational Method with Attention for High-Definition Face ... Abstract. We present a method based on four different neural network architectures to generate realistic high-resolution faces. Our model consists of four modules: a convolutional Variational Auto-Encoder (VAE), a convolutional pix2pix network, a super-resolution transformer, and a cross-scaling module. Our work combines a variational model with an attention model based on transformers to improve the quality of generated high-definition images that looks realistic.

Variational autoencoder for deep learning of images labels and captions
Regularizing Variational Autoencoder with Diversity and ... - DeepAI As one of the most popular generative models, Variational Autoencoder (VAE) approximates the posterior of latent variables based on amortized variational inference. However, when the decoder network is sufficiently expressive, VAE may lead to posterior collapse; that is, uninformative latent representations may be learned. A Semi-supervised Learning Based on Variational Autoencoder for Visual ... VAE [8] is a variant of Autoencoder that try to avoid overfitting in complex neural network and improve the ability of synthesis by encoding the data to a distribution of zinstead of a single point encoding. It has been successfully used in image generation [6, 14] and text generation [21]. Dimensionality Reduction Using Variational Autoencoders Variational autoencoder for deep learning of images, labels and captions a research by Pu et al. in 2016 mentioned development of a novel variational autoencoder which models images and the related features and captions. He used deep generative deconvolution neural network (DGDN) as the decoder of the latent image features and a deep convolution network (CNN) was used as the encoder for the image latent features . Roweis et al. in his report on Nonlinear Dimensionality Reduction by Locally ...
Variational autoencoder for deep learning of images labels and captions. Multi-modal data generation with a deep metric variational autoencoder We present a deep metric variational autoencoder for multi-modal data generation. The variational autoencoder employs triplet loss in the latent space, which allows for conditional data generation by sampling in the latent space within each class cluster. The approach is evaluated on a multi-modal dataset consisting of otoscopy images of the tympanic membrane with corresponding wideband tympanometry measurements. GitHub - wshahbaz/var_autoencoder: Convolutional Variational ... As the VAE trains, its generated images more closely resemble the input images and become sharper. Below is a visualization of the VAE's generated digits as it improves during training: 2D manifold of the digits from the latent space: References. Variational Autoencoder for Deep Learning of Images, Labels and Captions Disentangled variational autoencoder based multi-label classification ... We propose a novel framework for multi-label classification, Multivariate Probit Variational AutoEncoder (MPVAE), that effectively learns latent embedding spaces as well as label correlations. MPVAE learns and aligns two probabilistic embedding spaces for labels and features respectively. EOF
Dimensionality Reduction Using Variational Autoencoders Variational autoencoder for deep learning of images, labels and captions a research by Pu et al. in 2016 mentioned development of a novel variational autoencoder which models images and the related features and captions. He used deep generative deconvolution neural network (DGDN) as the decoder of the latent image features and a deep convolution network (CNN) was used as the encoder for the image latent features . Roweis et al. in his report on Nonlinear Dimensionality Reduction by Locally ... A Semi-supervised Learning Based on Variational Autoencoder for Visual ... VAE [8] is a variant of Autoencoder that try to avoid overfitting in complex neural network and improve the ability of synthesis by encoding the data to a distribution of zinstead of a single point encoding. It has been successfully used in image generation [6, 14] and text generation [21]. Regularizing Variational Autoencoder with Diversity and ... - DeepAI As one of the most popular generative models, Variational Autoencoder (VAE) approximates the posterior of latent variables based on amortized variational inference. However, when the decoder network is sufficiently expressive, VAE may lead to posterior collapse; that is, uninformative latent representations may be learned.
YUNCHEN PU | Duke University, North Carolina | DU
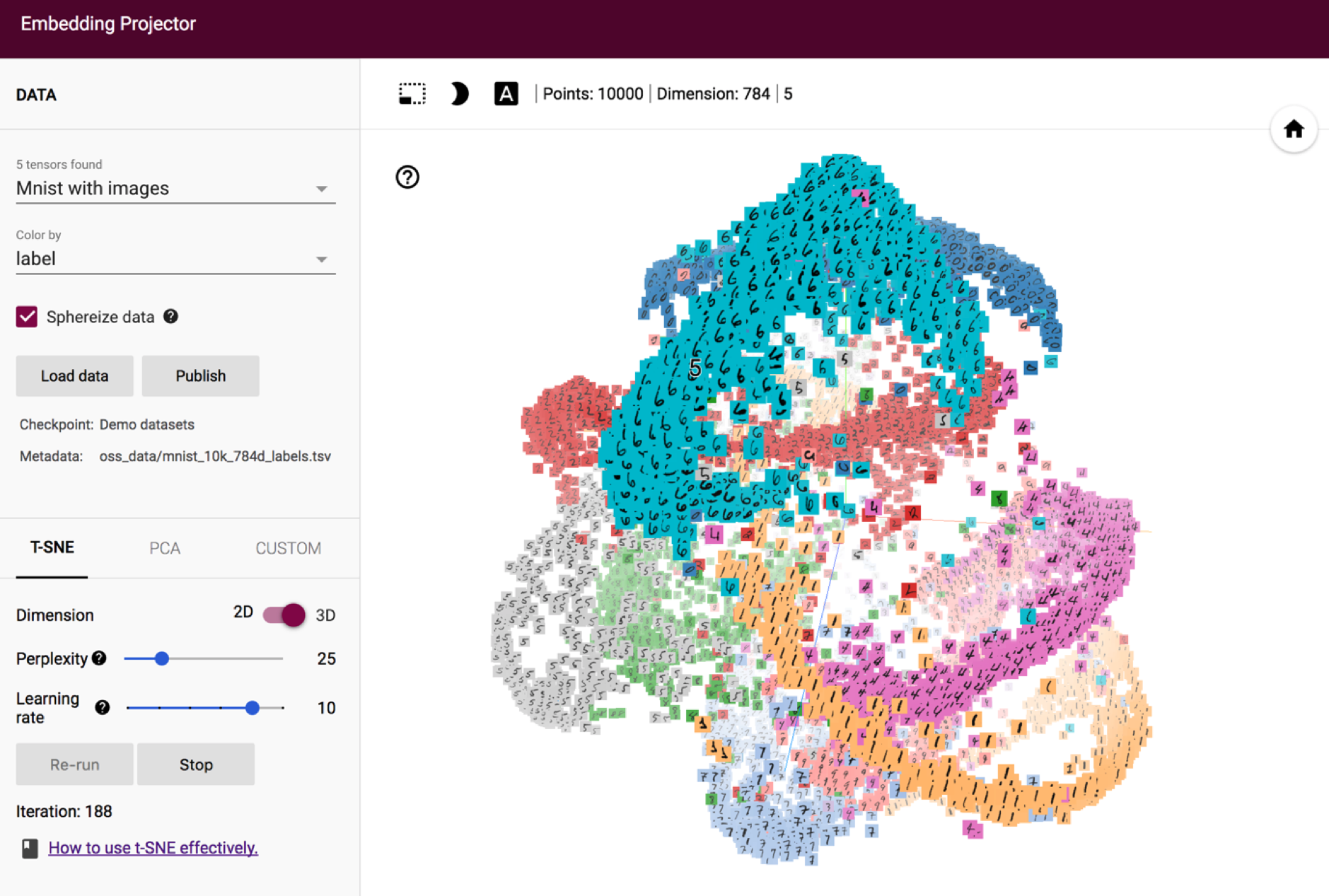
Unsupervised deep learning models used in computer vision — Steemit
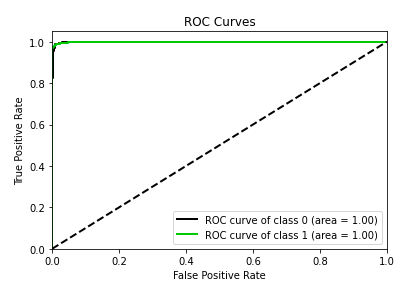
FaceMask Detection | Home

A plot of contrast-to-noise (a) and signal-to-noise (b) ratios compare... | Download Scientific ...
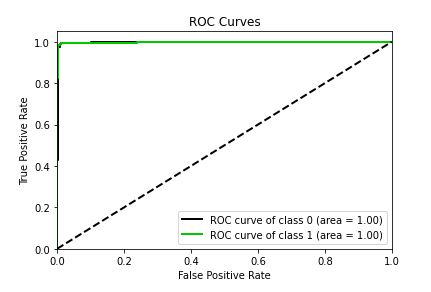
FaceMask Detection | Home

(PDF) Variational Autoencoder for Deep Learning of Images, Labels and Captions

a) Magnetic anomaly map of the model in Figure 2. b) Signum transform... | Download Scientific ...

Semi-supervised classification accuracy on the validation set of... | Download Scientific Diagram
Post a Comment for "41 variational autoencoder for deep learning of images labels and captions"